Announcing Lector: a content aggregator that puts you back in control
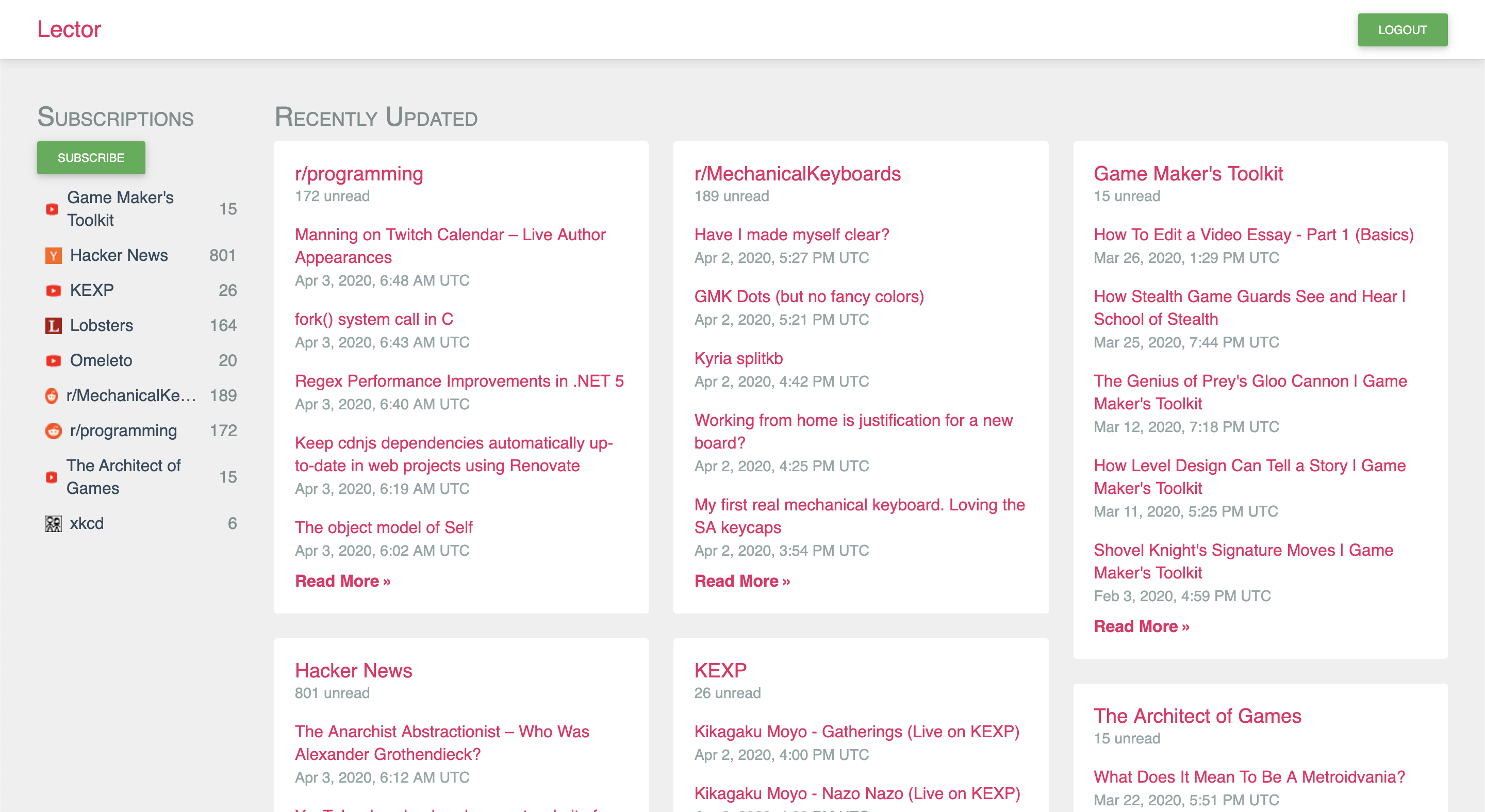
Welcome to Lector! A content aggregator that puts you back in control
Have you ever caught yourself mindlessly scrolling through social media, consuming content that you haven’t chosen to have on your timeline? Somehow the algorithms that be had mined enough data about you that they just knew what appeals to our lizard brains. I know this has happened to me, and even though a lot of times it’s content I’d probably have otherwise enjoyed, I can’t shake off the feeling that the computers are in control of the content I consume.
This has annoyed me enough for me to try to do something about it. And that is why I built 1 Lector. Lector is a content aggregator that puts you back in control of what you consume. You subscribe to the things you like, and it gives you a chronologically sorted timeline where you can mark the things you’ve read, and nothing else. No trending content, no suggestions, no sorting by top stories. It doesn’t track you, it doesn’t recommend anything to you, and it doesn’t show you any ads.
If you are not embarrassed by the first version of your product, you’ve launched too late
— Reid Hoffman, co-founder of LinkedIn
My goal is to make Lector able to subscribe to as much web content as possible. It currently only supports RSS and Atom feeds, despite the sad fact that fewer and fewer websites offer them anymore. You can check out the roadmap to see what’s planned out next. In the meantime, you can enjoy your feeds through the fastest the fastest web app I could come up with 2.
Are you interested in checking it out? Sign up for a trial account, and feel free to reach out with problems, questions or any other feedback.
Or re-built, rather. The original Lector went up back in 2013, built by Mauricio and me. The only surviving code is the feed ingestion engine, though. ↩︎
Lector ships exactly zero bytes of JavaScript right now, and if that ever changes, I’ll still aim to have it work with JavaScript disabled. ↩︎